Data Science life cycle process
A typical data science life cycle process involves:
1) Business Understanding
2) Data Acquisition and Understanding
3) Modeling
4) Deployment
5) Customer Acceptance
A typical interaction diagram is presented below from Azure Studio documentation.
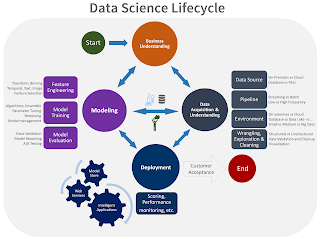
Business understanding is the first phase and is crucial to understand what is the problem we are trying to solve. This involves understanding stakeholder expectations, understand the data requirements to address the needs, sourcing the data (internal as well as external) and formulating the business goal to be achieved.
In the Data acquisition and understanding phase we concentrate on getting the data and this involves interaction with other application teams and external sources. This involves interaction with the ETL team to acquire, clean, transform and analyze the data (including visualization techniques).
The modeling phase is the one where a Data Scientist or a machine learning engineer typically work on their own. Feature engineering tasks are performed to understand which features are more relevant for the problem at hand and if any additional derived features need to be created for better solving the problem. This is followed by the model training part where a choice need to be made from a plethora of existing models and if needed form an ensemble of model that best answers the question in hand. This could be an Inference or Predication task. Several techniques, such as Cross Validation or A/B testing, are available to test the model performance before it is seen fit for production deployment.
The deployment phase involves interaction with the Dev-Ops team where the model gets integrated into an existing application. Model performance plays a crucial role and the execution time of the final algorithm need to be acceptable. Issues may occur here as the typical amount of data used during model development may be far less than what is used during the final runs in production. Many of the models tend to store the computational data in memory and may slow down the system considerably. This is particularly true for Decision Tree algorithms.
Customer acceptance phase involves meeting the requirements as defined in the business understanding phase. Several metrics are available to score the performance of the models that showcase how well the model meets the requirements. One needs to keep a constant watch on these metrics to ensure the model does not deviate beyond a set of threshold limits and if necessary continue to fine tune the model and the process repeats itself.
1) Business Understanding
2) Data Acquisition and Understanding
3) Modeling
4) Deployment
5) Customer Acceptance
A typical interaction diagram is presented below from Azure Studio documentation.

Business understanding is the first phase and is crucial to understand what is the problem we are trying to solve. This involves understanding stakeholder expectations, understand the data requirements to address the needs, sourcing the data (internal as well as external) and formulating the business goal to be achieved.
In the Data acquisition and understanding phase we concentrate on getting the data and this involves interaction with other application teams and external sources. This involves interaction with the ETL team to acquire, clean, transform and analyze the data (including visualization techniques).
The modeling phase is the one where a Data Scientist or a machine learning engineer typically work on their own. Feature engineering tasks are performed to understand which features are more relevant for the problem at hand and if any additional derived features need to be created for better solving the problem. This is followed by the model training part where a choice need to be made from a plethora of existing models and if needed form an ensemble of model that best answers the question in hand. This could be an Inference or Predication task. Several techniques, such as Cross Validation or A/B testing, are available to test the model performance before it is seen fit for production deployment.
The deployment phase involves interaction with the Dev-Ops team where the model gets integrated into an existing application. Model performance plays a crucial role and the execution time of the final algorithm need to be acceptable. Issues may occur here as the typical amount of data used during model development may be far less than what is used during the final runs in production. Many of the models tend to store the computational data in memory and may slow down the system considerably. This is particularly true for Decision Tree algorithms.
Customer acceptance phase involves meeting the requirements as defined in the business understanding phase. Several metrics are available to score the performance of the models that showcase how well the model meets the requirements. One needs to keep a constant watch on these metrics to ensure the model does not deviate beyond a set of threshold limits and if necessary continue to fine tune the model and the process repeats itself.
Comments
Post a Comment